Multigrid
Multigrid
Multigrid solvers are among the fastest known solvers for elliptic PDEs. We have published several pieces of work on algebraic-geometric multigrid, additive schemes mirroring multiplicative robustness, and parallelisation using inexact, iterative assembly. But one of the key things we haven’t completed yet is multigrid in combination with higher-order methods.
On the higher-order spatial side, i.e. for classic p-multigrid, there are a couple of techniques (e,g, HDG) for which we have prototypes of state-of-the-art algorithms and know that this fits to our geometric meshes that we use in Peano. Higher-order in time is a different story. Notably the ADER-DG scheme, i.e. how to couple it with a multigrid solver, is of particular interest to me. In classical Runge-Kutta methods, we have to solve one multigrid problem per shot if multigrid tackles and elliptic operator within the time stepping equation. Otherwise, the convergence order deteriorates.
It is an open question how to design a multigrid solver that fits to ADER-DG’s local implicit solves and higher-order prediction. However, I assume that we might need some local space-time multigrid plus plenty of HPC tricks that will have to be employed to make the arising schemes fast. Having such a solver would enable ExaHyPE to tackle a whole new class of problems. It also opens up a whole can of worms of HPC-related challenges including fast smoother implementation or GPU offloading as well as questions from the p-multigrid domain, which we now have to translate into a (local) space-time setting: what are good inter-grid transfer operators, how do we write efficient smoother, what does good software look like for these problems, can we work with reduced precision, and so forth.
Methodology
We have a preprint on a p-multigrid solver for classic DG
Implementation techniques for multigrid solvers for high-order Discontinuous Galerkin methods
This can provide a starting point supplementing relevant implementational building blocks. There are different ways to tackle the overall vision. One way certainly is to couple that directly with ExaHyPE in a classic RKDG setting. Here, we do, in principle, only textbook multigrid. However, such a coupling provides a solid (benchmarking) baseline, and it will already highlight some of the challenges that the final code will face, such as the fact that the solution changes only locally and therefore global smoothing might not be the best choice.
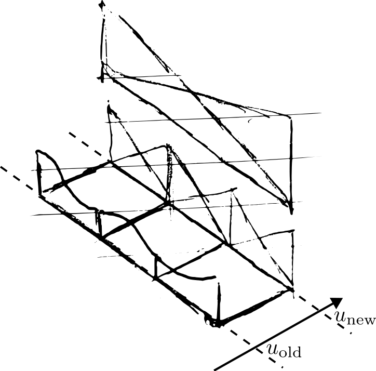
Image above: In naive time stepping methods, we do a time step from old to new solution and then apply the multigrid solver there to enforce a certain solution. That works fine for lower order time stepping. It also works for Runge-Kutta schemes, if we do the multigrid in each and every shot. However, it makes Runge-Kutta deteriorate to first order. However, we don’t want to call multigrid per subtrial, as this is very expensive. For ADER-DG, it is very likely that we will see a similar pattern: if we only do one multigrid “correction” in the end, then we will likely again see a deteriorating time integration accuracy. It is not clear “yet” how to do it properly for ADER-DG, but likely we will need some (local) space-time multigrid.
From there, the project would extend the Runge-Kutta type scheme into ADER-DG. Very likely it would pay off to do two things in parallel: First, think about how s RK shots can be coupled. We certainly don’t have to restart MG for each step separately. It is not even clear if we have to run all of multigrid for each shot. Maybe MG for the first one is sufficient and then we can use classic smoothing or some CG steps afterwards. Second, we take the ADER-DG formalism and transfer the RK insights into this domain. The appeal or ADER-DG is that it only needs on (logical) step with one single MPI data exchange between cells/subdomains to come up with a higher-order solution, whereas Runge-Kutta needs s exchanges and s (multigrid) solves. If we can phrase the solve over ADER-DG as a space-time multigrid solver, we might be able to get away with a single multigrid solve here as well.
Related work
Implementation techniques for multigrid solvers for high-order Discontinuous Galerkin methods – not published yet as there are still a few flaws in there, but sets the tone re p-multigid
Lazy Stencil Integration in multigrid algorithms – interesting paper in the RK context as it kind of challenges that each and every operator has to be assembled super accurately right from the start
Stabilized Asynchronous Fast Adaptive Composite Multigrid using Additive Damping – relevant, as it is not clear if multiplicative multigrid is the right choice for the present challenge. It might be that additive is faster even as solver, but if and only if we eliminate its instabilities.
Delayed approximate matrix assembly in multigrid with dynamic precisions – similar to the lazy paper above, it is not clear if need full precision for the multigrid solver right from the start. So an interesting case for the use of dynamic reduced precision.
A Geometric Space-time Multigrid Algorithm for the Heat Equation – an older paper, but in the context of ADER-DG and RK, it suddenly gains relevance: do we really have to solve each stage of RK with a full-blown multigrid code?
Complex additive geometric multilevel solvers for Helmholtz equations on spacetrees – seems to be slightly off topic, but the explanation of the additive scheme is spot-on.
Quasi-matrix-free hybrid multigrid on dynamically adaptive Cartesian grids – still maybe my favourite MG piece of work which brings together the robustness of algebraic operators with a purely geometric mindset.
