Time stepping
Time stepping optimisation
Explicit time stepping schemes dominate the world of hyperbolic equation system solvers, as we find them in ExaHyPE. If we used implicit time stepping, we would have to solve an equation system per time step, and these global equation systems are simply too large to solve for many of the applications I am interested in. So explicit it is.
These explicit solvers in my group typically use either fixed time stepping — where all parts of the mesh advance in time at the same rate — or something like bucketed time stepping. In the latter, finer mesh parts advance with smaller time step sizes, but there is a global reference time step size, and “smaller” means a fixed fraction of that reference size, often dictated exclusively by the mesh resolution. We also have some examples where mesh parts can advance in time entirely anarchically, anticipating the information propagation speed of the physics, but these rarely outperform other solvers.
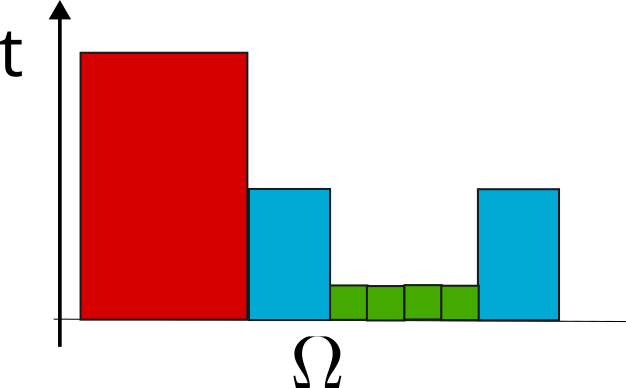
The illustration above shows how such adaptive (bucketed) time stepping typically works: the large red cell (this is a 1D example with time on the vertical axis) advances in time with a large step. The blue cells take only half the time step size and therefore need two steps to catch up. Before they can take their second step, however, the green cells must follow with tiny steps.
All of these local time stepping schemes face at least two serious challenges from an HPC perspective:
- The load balancing is hard.
- Any efficiency gains from only advancing cells where “things happen” are eaten up by administrative overhead and the fact that GPUs are particularly well-suited to large, regular workloads — not irregular, fine-grained ones.
Even if local time stepping does not yield a speedup, there may still be a numerical case for implementing it. However, a further major challenge with explicit time stepping is that explicit schemes struggle with stiff PDEs, and most of the problems I am interested in can become very stiff. It is therefore worth considering implicit-explicit schemes.
Ambition
We want to study whether we can construct time stepping schemes that are faster than anything currently available, and in many cases as robust as implicit schemes, by combining several different ideas:
- If we can identify clusters of cells in a mesh that form a connected domain, we can deploy each cluster to a compute unit (a task on the CPU or GPU). The cluster interacts with its surroundings only through its faces, meaning we can launch it and let it advance in time independently. Within the cluster, we can prioritise the cells along its boundary — similar to diamond tiling for stencils — so that the cluster’s face data is produced as early as possible, and the cluster interior follows afterwards.
- Any explicit DG-like time stepping evolves a cell under the assumption that its neighbours do not move: fluxes across a face are computed using the neighbour’s state from the previous time step. An implicit scheme could therefore be constructed by advancing a cell, then its neighbour, and then recomputing the original cell, iterating until the scheme converges, i.e. until the solution no longer changes. This is closely related to domain decomposition. Globally, such an approach is computationally infeasible. However, if interesting dynamics are confined to a cluster, we can treat the interior of that cluster implicitly while handling the rest of the mesh explicitly. In other words, we solve everything within the cluster implicitly, on the assumption that significant signals do not leave the cluster within a single time step.
In the illustration above, the subdomain bounded by the two blue cells could be deployed to a GPU. The GPU advances the blue cells and returns the result, which feeds into the solution of the red cell. Meanwhile, the GPU continues advancing the green cells. By the time the CPU has completed some post-processing — and advanced the remainder of the domain, not shown here — the entire cluster of green and blue cells has caught up. Finding such clusters is non-trivial, and they may also change over time.
In the same example, one could also envisage a scheme in which the cluster of blue and green cells is advanced using implicit time stepping, simply by adding an outer iteration loop. Globally, the scheme remains explicit, but clusters are treated differently internally. If a fast signal traverses the green cells, it can be captured accurately and stably — and the red cell need never be aware of it.
Work programme
The work programme naturally decomposes into a sequence of steps:
- We need the technical infrastructure to identify clusters on-the-fly and let them time step en bloc.
- Then we construct an algorithm and implementation that prioritises a cluster’s boundary cells and sends these boundaries back to other clusters/the mesh before we continue time stepping.
- Finally, this kernel should be allowed to switch to an implicit scheme internally.
The work has to be accompanied by a couple of performance tweaking steps:
- Can we tweak the cluster identification such that the cluster shapes and sizes are optimised?
- Can we deploy clusters to GPUs?
- Can we use ML techniques to construct a good guess of the solution over a cluster, i.e. can we speed up the initial guess feeding into an implicit time stepping scheme?
Preparatory work
There is plenty of literature around local time stepping. The most relevant papers for the ExaHyPE/Peano context are the papers around from the SeisSol code. The identification of cells that could form a cluster has been published before
So the identification of “good” cells that could form a cluster is there. What is not there yet is the glueing of these cells together and then the actual algorithms on top of these cell assemblies. The fundamental paradigm how to identify cells that could form a cluster has first been published in SISC as
Enclave Tasking for DG Methods on Dynamically Adaptive Meshes
and then we have another paper draft which never made it into publication unfortunately: Stop talking to me — a communication-avoiding ADER-DG realisation. That last one demonstrates that coupling between cells can be done solely through face data structures, i.e. that idea that a cluster only has to deliver data on its boundaries to let the remainder of the mesh progress in time is validated, too.
